*Tensorflow 1.9 버전 튜토리얼
1. 윈도우에 Tensorflow GPU 버전 설치하기
2 딥러닝 slim 라이브러리 설치, 학습, 평가하기
3. 내 이미지로 학습 하기 ( caltech 이미지 사용 )
4. 학습된 모델 사용하기
1. 윈도우에 Tensorflow GPU 버전 설치하기
2.1 딥러닝 slim 라이브러리 설치 및 이미지 셋 다운로드
2.2 딥러닝 모델 학습하기
2.3 딥러닝 모델 평가하기
3. 내 이미지로 학습 하기 ( caltech 이미지 사용 )
4. 학습된 모델 사용하기
2장까지 slim 모델을 이용해 flower 이미지를 학습하고 평가까지 실습 해 보았습니다. 코드 내용은 잘 모르지만 어쨋든 우리는 딥러닝(CNN)을 실제 사용해 본 것입니다. 그럼 우리가 원하는 이미지들에 대해서는 어떻게 학습 시킬 수 있을까요? 그 힌트는 우리가 직접 실습해본 flower 예제 파일에 있습니다. flower 예제 파일만 참고하여 응용하면 되기 때문입니다.
Caltech-256 Object Category Dataset
다운로드 링크 : http://www.vision.caltech.edu/Image_Datasets/Caltech256/256_ObjectCategories.tar
관련 정보 링크
: http://authors.library.caltech.edu/7694/
257 카테고리로 이미지가 분류되어 제공되는 이미지 데이터 셋입니다. 압축된 상태에서 전체 파일 용량은 1.1GB 입니다. 총 이미지 수는 3만607개이고, 한 분류당 최대 827개, 최소 80개의 다양한 사이즈의 이미지로 구성되어 있습니다.

다운로드 받은 파일을 d:\tmp 폴더에 압축을 풀겠습니다.
flowers 이미지를 TFRecord로 변환시켰던 실습을 기억하실 겁니다.( 2.1절 ) 그 때 사용된 코드를 약간 변형 시켜 보겠습니다.
그에 앞서 Caltech 이미지를 Flowers 이미지와 같은 형태로 폴더 구성을 먼저 해보겠습니다. 먼저 D:\tmp 폴더의 Flowers 폴더의 구조를 살펴 보겠습니다.

Flowers 폴더 하위에 Flowers_photos 폴더가 있고 그 하위에 각 category 별로 이미지들이 분류되어 저장되어 있는 것을 볼 수 있습니다. Caltech도 똑같이 구성해 보겠습니다.

D:\tmp 폴더 하위에 기존 256_ObjectCategories 폴더의 이름을 caltech256으로 변경하고 그 하위 폴더의 256_ObjectCategories 폴더 이름을 caltech256_photos로 변경하였습니다.
* download_and_convert_data.py 수정
위 파일은 지정한 이미지 데이터 셋을 다운로드하고 TFRecord 형태로 변환시키는 코드입니다. 우리는 이미지를 이미 수동으로 다운로드 받아 준비했기 때문에 TFRecord로 변환만 시키면 됩니다. 기존 Flowers 라는 키워드로 변환되게 작동하던 코드를 caltech256 이라는 키워드로 작동 될 수 있게 코드를 수정해보겠습니다!
앞절에 이어 Caltech 이미지들을 TFRecord 형태로 변환 시키기 위해 download_and_convert_data.py 코드를 Spyder로 열어 분석 해보겠습니다.

39~41, 62~67 라인을 보면 각각의 이미지 셋에 대응하는 또다른 python 코드들이 할당 되어 있는 것을 볼 수 있습니다. 우리는 Caltech256 이라는 키워드를 사용할 것이기 때문에 기존 코드에 Caltech256 관련 코드를 추가해 보겠습니다.

위와 42라인, 69~70라인에 clatech256 키워드가 작동하도록 코드를 추가하고 저장하세요.
slim 모델 폴더에 보면 datasets 라는 폴더가 보일 겁니다. 그 안에 보면 아래와 같은 파일들로 구성되어 있습니다.
오호라... 딱 보니 각 이미지셋 마다 대응되는 파일들이 만들어져 있네요. 그럼 같은 형태로 Caltech256 파일도 만들어주면 되겠습니다. 우리는 현재 Flowers를 참고해서 만들고 있기 때문에 download_and_convert_flowers.py 를 복사해서 이름을 download_and_convert_caltech256.py로 변경하겠습니다. 동일하게 flowers.py를 복사해서 이름을 caltech256.py로 변경 하겠습니다.

그럼 download_and_convert_caltech256.py 파일을 Spyder로 열어서 살펴보겠습니다.
코드를 수정하면서 진행하기 때문에 코드 라인넘버는 무시하고 키워드를 보면서 본인의 실습 코드를 수정하기 바랍니다.
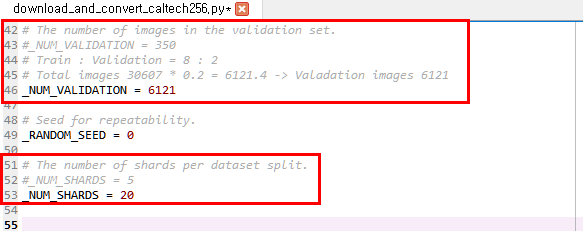
처음 변경해야 하는 코드는 _NUM_VALIDATION 입니다. 기존 flower 이미지에서는 350으로 설정되어 있었습니다. 설정 값의 의미는 TFRecord 형태의 파일로 변환 할때 Train 용 파일과 Validation 파일용으로 따로 변환하게 되는데 이때 Validation에 해당하는 파일에 몇개의 이미지를 할당할것인지 정하는 값입니다. 우리는 Caltech256 이미지가 총 30607개이고 여기에서 20%에 해당하는 6121개의 이미지를 Validation 용으로 할당하겠습니다.
다음 코드는 _NUM_SHARDS 입니다. Flowers 이미지는 5라는 값이 설정되어 있었습니다. 실제 tmp\flowers\ 폴더에 가보면 TFRecord로 변환된 이미지 파일이 Train/Validation 각각 5개의 파일로 변환되어 있는 것을 볼 수 있습니다. Train의 파일 하나가 40MB 정도 되네요. 그럼 Caltech256 전체 이미지 용량이 1.1GB 정도 되니 20을 설정하면 Train 파일 하나당 40MB 정도 될거 같네요.
다음은 def _get_filenames_and_classes(dataset_dir): 함수를 수정해 보겠습니다. 위와 같이 flower라는 단어가 보일 겁니다. 아래와 같이 flower 를 caltech256으로 변경하겠습니다.


마지막으로 바꿀 코드는 아래와 같습니다. TFRecord 형태의 출력 파일 이름을 설정하는 코드 입니다. flowers 를 caltech256으로 변경하고 저장해주세요.



이번 파일에서는 딱 3줄만 변경하면 됩니다. 우선 32라인의 flowers를 caltech256으로 변경하세요. 다음 SPLITS_TO_SIZES의 validation 값은 기존 350에서 6121로 변경하고, train 값은 3320에서 24486으로 변경하겠습니다.(30607 - 6121) 마지막으로 _NUM_CLASSES는 분류되어 있는 category 갯수로 바꾸면 되는데 caltech256은 257 categories 이기 때문에 257로 변경하고 저장하겠습니다.

다 됐을까요? 다 변경 한 것인가요??? 파일 하나 더 변경해야 합니다!
이제 진짜 마지막 파일입니다. 힘을 냅시다. Spyder로 dataset_factory.py를 열어 보겠습니다. 오 아주 간단하게 추가만 하면 되겠네요. 아래와 같이 추가하고 저장하세요.

드디어 TFRecord 파일로 변환을 시켜 보겠습니다. slim 폴더로 이동해서 아래 코드를 실행 시켜 보세요.


caltech 이미지중 56번 dog category 폴더에 greg 라는 파일이... 이미지 파일이 아니라 폴더 이름입니다. 지워버리세요!
다시 코드를 실행하겠습니다. 또 에러입니다. 이번엔 JPG 파일이 아니네요. 198번 spider category 폴더에 RENAME2라는 파일이 있습니다. 지워버리세요!


이제 학습을 해보겠습니다. 2.2절 모델 학습하기 실습 중 2) Fine-tuning a model from an existing checkpoint 에서 사용한 방법으로 학습을 진행 하겠습니다.
python train_image_classifier.py
--train_dir=\tmp\train_inception_v1_caltech256_FineTune_logs
--dataset_name=caltech256
--dataset_split_name=train
--dataset_dir=\tmp\caltech256
--model_name=inception_v1
--checkpoint_path=\tmp\my_checkpoints/inception_v1.ckpt
--checkpoint_exclude_scopes=InceptionV1/Logits
--trainable_scopes=InceptionV1/Logits
--max_number_of_steps=1000
--batch_size=16
--learning_rate=0.01
--learning_rate_decay_type=fixed
--save_interval_secs=60
--save_summaries_secs=60
--log_every_n_steps=100
--optimizer=rmsprop
--weight_decay=0.00004



1. 윈도우에 Tensorflow GPU 버전 설치하기
2 딥러닝 slim 라이브러리 설치, 학습, 평가하기
3. 내 이미지로 학습 하기 ( caltech 이미지 사용 )
4. 학습된 모델 사용하기
1. 윈도우에 Tensorflow GPU 버전 설치하기
2.1 딥러닝 slim 라이브러리 설치 및 이미지 셋 다운로드
2.2 딥러닝 모델 학습하기
2.3 딥러닝 모델 평가하기
3. 내 이미지로 학습 하기 ( caltech 이미지 사용 )
4. 학습된 모델 사용하기
2장까지 slim 모델을 이용해 flower 이미지를 학습하고 평가까지 실습 해 보았습니다. 코드 내용은 잘 모르지만 어쨋든 우리는 딥러닝(CNN)을 실제 사용해 본 것입니다. 그럼 우리가 원하는 이미지들에 대해서는 어떻게 학습 시킬 수 있을까요? 그 힌트는 우리가 직접 실습해본 flower 예제 파일에 있습니다. flower 예제 파일만 참고하여 응용하면 되기 때문입니다.
- 실습에 사용할 내 이미지 다운로드
Caltech-256 Object Category Dataset
다운로드 링크 : http://www.vision.caltech.edu/Image_Datasets/Caltech256/256_ObjectCategories.tar
관련 정보 링크
: http://authors.library.caltech.edu/7694/
257 카테고리로 이미지가 분류되어 제공되는 이미지 데이터 셋입니다. 압축된 상태에서 전체 파일 용량은 1.1GB 입니다. 총 이미지 수는 3만607개이고, 한 분류당 최대 827개, 최소 80개의 다양한 사이즈의 이미지로 구성되어 있습니다.

다운로드 받은 파일을 d:\tmp 폴더에 압축을 풀겠습니다.
- Caltech 이미지 폴더 변경하기
flowers 이미지를 TFRecord로 변환시켰던 실습을 기억하실 겁니다.( 2.1절 ) 그 때 사용된 코드를 약간 변형 시켜 보겠습니다.
그에 앞서 Caltech 이미지를 Flowers 이미지와 같은 형태로 폴더 구성을 먼저 해보겠습니다. 먼저 D:\tmp 폴더의 Flowers 폴더의 구조를 살펴 보겠습니다.

Flowers 폴더 하위에 Flowers_photos 폴더가 있고 그 하위에 각 category 별로 이미지들이 분류되어 저장되어 있는 것을 볼 수 있습니다. Caltech도 똑같이 구성해 보겠습니다.

D:\tmp 폴더 하위에 기존 256_ObjectCategories 폴더의 이름을 caltech256으로 변경하고 그 하위 폴더의 256_ObjectCategories 폴더 이름을 caltech256_photos로 변경하였습니다.
- TFRecord 형태로 변환하기
* download_and_convert_data.py 수정
위 파일은 지정한 이미지 데이터 셋을 다운로드하고 TFRecord 형태로 변환시키는 코드입니다. 우리는 이미지를 이미 수동으로 다운로드 받아 준비했기 때문에 TFRecord로 변환만 시키면 됩니다. 기존 Flowers 라는 키워드로 변환되게 작동하던 코드를 caltech256 이라는 키워드로 작동 될 수 있게 코드를 수정해보겠습니다!
- download_and_convert_data.py 코드 변경
앞절에 이어 Caltech 이미지들을 TFRecord 형태로 변환 시키기 위해 download_and_convert_data.py 코드를 Spyder로 열어 분석 해보겠습니다.

39~41, 62~67 라인을 보면 각각의 이미지 셋에 대응하는 또다른 python 코드들이 할당 되어 있는 것을 볼 수 있습니다. 우리는 Caltech256 이라는 키워드를 사용할 것이기 때문에 기존 코드에 Caltech256 관련 코드를 추가해 보겠습니다.

위와 42라인, 69~70라인에 clatech256 키워드가 작동하도록 코드를 추가하고 저장하세요.
- slim\datasets\ 에 Caltech 파일 만들기
slim 모델 폴더에 보면 datasets 라는 폴더가 보일 겁니다. 그 안에 보면 아래와 같은 파일들로 구성되어 있습니다.

오호라... 딱 보니 각 이미지셋 마다 대응되는 파일들이 만들어져 있네요. 그럼 같은 형태로 Caltech256 파일도 만들어주면 되겠습니다. 우리는 현재 Flowers를 참고해서 만들고 있기 때문에 download_and_convert_flowers.py 를 복사해서 이름을 download_and_convert_caltech256.py로 변경하겠습니다. 동일하게 flowers.py를 복사해서 이름을 caltech256.py로 변경 하겠습니다.

- download_and_convert_caltech256.py 파일 수정하기
그럼 download_and_convert_caltech256.py 파일을 Spyder로 열어서 살펴보겠습니다.

코드를 수정하면서 진행하기 때문에 코드 라인넘버는 무시하고 키워드를 보면서 본인의 실습 코드를 수정하기 바랍니다.
처음 변경해야 하는 코드는 _NUM_VALIDATION 입니다. 기존 flower 이미지에서는 350으로 설정되어 있었습니다. 설정 값의 의미는 TFRecord 형태의 파일로 변환 할때 Train 용 파일과 Validation 파일용으로 따로 변환하게 되는데 이때 Validation에 해당하는 파일에 몇개의 이미지를 할당할것인지 정하는 값입니다. 우리는 Caltech256 이미지가 총 30607개이고 여기에서 20%에 해당하는 6121개의 이미지를 Validation 용으로 할당하겠습니다.
다음 코드는 _NUM_SHARDS 입니다. Flowers 이미지는 5라는 값이 설정되어 있었습니다. 실제 tmp\flowers\ 폴더에 가보면 TFRecord로 변환된 이미지 파일이 Train/Validation 각각 5개의 파일로 변환되어 있는 것을 볼 수 있습니다. Train의 파일 하나가 40MB 정도 되네요. 그럼 Caltech256 전체 이미지 용량이 1.1GB 정도 되니 20을 설정하면 Train 파일 하나당 40MB 정도 될거 같네요.
다음은 def _get_filenames_and_classes(dataset_dir): 함수를 수정해 보겠습니다. 위와 같이 flower라는 단어가 보일 겁니다. 아래와 같이 flower 를 caltech256으로 변경하겠습니다.


마지막으로 바꿀 코드는 아래와 같습니다. TFRecord 형태의 출력 파일 이름을 설정하는 코드 입니다. flowers 를 caltech256으로 변경하고 저장해주세요.


- caltech256.py 코드 변경

이번 파일에서는 딱 3줄만 변경하면 됩니다. 우선 32라인의 flowers를 caltech256으로 변경하세요. 다음 SPLITS_TO_SIZES의 validation 값은 기존 350에서 6121로 변경하고, train 값은 3320에서 24486으로 변경하겠습니다.(30607 - 6121) 마지막으로 _NUM_CLASSES는 분류되어 있는 category 갯수로 바꾸면 되는데 caltech256은 257 categories 이기 때문에 257로 변경하고 저장하겠습니다.

다 됐을까요? 다 변경 한 것인가요??? 파일 하나 더 변경해야 합니다!
- dataset_factory.py 코드 변경
이제 진짜 마지막 파일입니다. 힘을 냅시다. Spyder로 dataset_factory.py를 열어 보겠습니다. 오 아주 간단하게 추가만 하면 되겠네요. 아래와 같이 추가하고 저장하세요.

- TFRecord 변환하기(download_and_convert_data.py 실행)
드디어 TFRecord 파일로 변환을 시켜 보겠습니다. slim 폴더로 이동해서 아래 코드를 실행 시켜 보세요.
python download_and_convert_data.py --dataset_name=caltech256 --dataset_dir=/tmp/caltech256
아... 변환이 잘 되는 듯 하다 에러가 나네요. 제가 이 에러 잡으려고 삽질 많이 했습니다. 어떤 문제인지 확인 하기 위해 datasets 폴더의 download_and_convert_caltech256.py 코드에 현재 변환되고 있는 이미지 파일 이름을 표시하도록 아래와 같이 수정하겠습니다.
자 다시 아래 코드를 실행 시켜 보겠습니다.
python download_and_convert_data.py --dataset_name=caltech256 --dataset_dir=/tmp/caltech256
어떤 이미지에서 에러가 났는지 잡았습니다!

다시 코드를 실행하겠습니다. 또 에러입니다. 이번엔 JPG 파일이 아니네요. 198번 spider category 폴더에 RENAME2라는 파일이 있습니다. 지워버리세요!

자 다시 아래 코드를 실행 시켜 보겠습니다.
python download_and_convert_data.py --dataset_name=caltech256 --dataset_dir=/tmp/caltech256
변환에 성공 했습니다! 아래 폴더에 보면 아래화면과 같이 TFRecord로 변환된 파일이 생성된 것을 확인할 수 있습니다!

- 학습하기
- 학습 1번 과정 #Fine-tune only the new layers for 1000 steps.
python train_image_classifier.py
--train_dir=\tmp\train_inception_v1_caltech256_FineTune_logs
--dataset_name=caltech256
--dataset_split_name=train
--dataset_dir=\tmp\caltech256
--model_name=inception_v1
--checkpoint_path=\tmp\my_checkpoints/inception_v1.ckpt
--checkpoint_exclude_scopes=InceptionV1/Logits
--trainable_scopes=InceptionV1/Logits
--max_number_of_steps=1000
--batch_size=16
--learning_rate=0.01
--learning_rate_decay_type=fixed
--save_interval_secs=60
--save_summaries_secs=60
--log_every_n_steps=100
--optimizer=rmsprop
--weight_decay=0.00004
python train_image_classifier.py --train_dir=\tmp\train_inception_v1_caltech256_FineTune_logs --dataset_name=caltech256 --dataset_split_name=train --dataset_dir=\tmp\caltech256 --model_name=inception_v1 --checkpoint_path=\tmp\my_checkpoints\inception_v1.ckpt --checkpoint_exclude_scopes=InceptionV1/Logits --trainable_scopes=InceptionV1/Logits --max_number_of_steps=1000 --batch_size=16 --learning_rate=0.01 --learning_rate_decay_type=fixed --save_interval_secs=60 --save_summaries_secs=60 --log_every_n_steps=100 --optimizer=rmsprop --weight_decay=0.00004
학습이 잘 이루어졌습니다.

- 학습 2번 과정 # Fine-tune all the new layers for 500 steps.
python train_image_classifier.py
--train_dir=\tmp\train_inception_v1_caltech256_FineTune_logs\all
--dataset_name=caltech256
--dataset_split_name=train
--dataset_dir=\tmp\caltech256
--model_name=inception_v1
--checkpoint_path=\tmp\train_inception_v1_caltech256_FineTune_logs
--max_number_of_steps=500
--batch_size=16
--learning_rate=0.0001
--learning_rate_decay_type=fixed
--save_interval_secs=60
--save_summaries_secs=60
--log_every_n_steps=10
--optimizer=rmsprop
--weight_decay=0.00004
python train_image_classifier.py --train_dir=\tmp\train_inception_v1_caltech256_FineTune_logs\all --dataset_name=caltech256 --dataset_split_name=train --dataset_dir=\tmp\caltech256 --model_name=inception_v1 --checkpoint_path=\tmp\train_inception_v1_caltech256_FineTune_logs --max_number_of_steps=500 --batch_size=16 --learning_rate=0.0001 --learning_rate_decay_type=fixed --save_interval_secs=60 --save_summaries_secs=60 --log_every_n_steps=10 --optimizer=rmsprop --weight_decay=0.00004
학습이 잘 이루어졌습니다.

- 평가하기
2.3절에서 3번 모델 평가 방법으로 코드를 실행해 보겠습니다.
python eval_image_classifier.py
--alsologtostderr
--checkpoint_path=\tmp\train_inception_v1_caltech256_FineTune_logs\all\
--dataset_dir=\tmp\caltech256
--dataset_name=caltech256
--dataset_split_name=validation
--model_name=inception_v1
python eval_image_classifier.py –alsologtostderr --checkpoint_path=\tmp\train_inception_v1_caltech256_FineTune_logs\all\ --dataset_dir=\tmp\caltech256 --dataset_name=caltech256 --dataset_split_name=validation --model_name=inception_v1
모델 예측 정확도 평가가 나왔습니다.

학습하는데 10분도 사용하지 않았는데 TOP 5 예측 정확도가 90.5%가 나옵니다.
이상 TF-slim 모델을 응용해 Caltech 256 이미지를 학습시키고 평가까지 해보았습니다. 지금의 3장을 잘 응용하면 자신이 원하는 이미지에 얼마든지 딥러닝을 적용 시켜 볼 수 있을 겁니다!
질문은 댓글로 주세요.











안녕하세요. 덕분에 flower영상에 대한 학습과 평가까지 무사히 마쳤습니다.
답글삭제그런데, 이제 caltech256 학습을 실습하는 중에 질문사항이 있어 두가지 드립니다.
먼저 1) download_and_convert_caltech256.py의 40행에 보면, _DATA_URL 정의가 있습니다. 기존에는 flower 영상링크가 있을텐데, caltech영상이 있는 영상링크로 변경하는게 맞는지요?
2) caltech256 post 내용대로 caltech256영상을 다운받고 압축푼후 디렉토리명도 변경했는데, download_and_convert_data.py를 실행하면 다시 다운받는데, 그럼 앞의 작업은 필요없는거 아닌가요? 두번 작업하는거 같아서요.
답변에 미리 감사드립니다.^^
앗! Caltech 이미지를 수동으로 이미 다운 받았기 때문에... 기존 코드의 URL 및 다운로드는 할 필요가 없습니다.
삭제download_and_convert_caltech256.py 의 190번 라인에 보면
dataset_utils.download_and_uncompress_tarball(_DATA_URL, dataset_dir)
코드가 있는데 제일 앞에 #로 주석 처리 해주세요. ㅎㅎ 본문에는 적지 않았네요.^^;
안녕하세요? caltech256 이미지들의 크기가 다 제각각인거같은데 변환을 하면 한 파일당 사이즈가 어떻게변하는지 알 수 있을까요??
답글삭제224 X 224로 변환이 되는것 같습니다~ 답글 늦어서 죄송~ㅎ
삭제안녕하세요 우선 항상 블로그에서 많은 도움되어 감사드립니다.
답글삭제tfrecord 작업에서 위에 게시물과 똑같이 따라해보았는데 Caltech256이 아닌 MNIST dataset이 계속해서 변환되어 저장되네요... 이런부분에 있어 해결방법이 있을까요?
안녕하세요~
삭제download_and_convert_caltech256.py 의 190번 라인에 보면
dataset_utils.download_and_uncompress_tarball(_DATA_URL, dataset_dir)
코드가 있는데 제일 앞에 #로 주석 처리 해주세요.
그외에는 위 블로그 내용대로 하면 될거에요~
inception 모델 말고 다른 모델로 바꿀 수 있나요??
답글삭제vgg 모델을 사용하려고 하는데 바꿀 수 있는지 궁금합니다.
물론이죠~ slim 폴더에 보면 nets라는 폴더가 있습니다. 그 안에 있는 네트워크는 다 쓸 수 있어요~ mobilenet도 쓸 수 있고, 심지어 dcgan도 있네요~
삭제제가 사용하는 이미지를 이미 폴더화 시켜서 라벨별로 구분을 했다면 변환시에도 폴더별로 저장이되나요>?? 아니면 폴더별로 한번씩 변환을 하면서 제가 새폴더에 저장을 해야하나요????
답글삭제tfrecord 로 변환이 되는데요~ 라벨별로 구분된 폴더에서 참조해서 여러개의 tfrecord 파일로 알아서 다 저장이 되요~ 라벨별 폴더 구분만 신경써주면 되고 나머지는 신경 쓸 필요 없답니다.
삭제질문이 있습니다. 알려주신대로 먼저 1000 스텝을 학습한후, 500스텝을 전체 학습 시켰는데, 기록하신 바와 같이 모델 예측 정확도가 90%가 안나오고, 두번을 반복 학습시켰는데, 각각 30%, 70% 정도 나오고, recall은 50%, 93% 가 나왔씁니다. 위에서 언급하신 내용 말고 다른 것을 또 수정해야 하나요? 제가 사용하는 환경은 tensorflow 1.7 gpu 버전, 파이썬은 3.5 버전을 사용하고 있습니다.
답글삭제500스텝보다 더 많은 스텝을 학습 시키면 더 높은 정확도를 얻을 수 있을 거에요~
삭제혹시 이미지에서 해당 사물의 위치를 찾아주는 학습도 시킬 수 있나요??? 할 수 있다고 말만 들었는데 막막하네요. 사물 분류도 님 계시물 보고 겨우 해볼만은 하겠다 라는 생각 들었는데 ㅜㅜ
답글삭제Object Detection을 해야 할거 같은데.. 저도 아직 안해봤어요~ 다음 포스팅 주제로 한번 준비해 볼게요~
삭제혹시 학습한 내용이 올바른 학습을 했는지 확인 할 수 있는 방법이 있을까요?
답글삭제작년에도 대학교 학부 졸업 준비하면서 많이 참고했었는데, 올해도 많은 도움 받고 가네요 ㅎㅎ 다른 튜토리얼들보다 훨씬 상세하고 따라하기 쉽게 잘 쓰신거같습니다~ 감사해요!
답글삭제작성자가 댓글을 삭제했습니다.
답글삭제혹시 vgg모델로 retrain한다고 했을때는 어떻게 하면되나요?
답글삭제File "download_and_convert_data.py", line 42, in
답글삭제from datasets import download_and_convert_food
File "C:\Users\momo7\Downloads\models-master\models-master\research\slim\datasets\download_and_convert_food.py", line 137
sys.stdout.flush()
^
SyntaxError: invalid syntax
tfrecord로 변환하려하면 이렇게 뜨는데 문제가 무엇일까요?
ValueError: No data files found in \tmp\caltech256\flowers_train_*.tfrecord
삭제라는 오류가 있는데 flowers_train_*.tfrecord는 어디서 수정해야하는거죠?
작성자님은 이미 해결하셨겠지만.. 다른 분을 위해 답글 남깁니다.
삭제ValueError: No data files found in \tmp\caltech256\flowers_train_*.tfrecord
이 에러가 발생하신 분들은 slim\datasets 폴더에 caltech256.py를 열어서 33 라인에
_FILE_PATTERN = 'caltech256_%s_*.tfrecord'로 바꾸시면 됩니다.
작성자가 댓글을 삭제했습니다.
답글삭제안녕하세요. 혹시 bmp로 Input Image를 사용하려고 하는데 방법이 있을까요 ..?
답글삭제그리고 1채널로 바꿀시에 문제가 생기는데 해결법 아시나요..?