
* Tensorflow 1.9 업그레이드 이후 Slim을 사용하기 위한 튜토리얼 리비전 입니다.
1. 윈도우에 Tensorflow GPU 버전 설치하기
2 딥러닝 slim 라이브러리 설치, 학습, 평가하기
3. 내 이미지로 학습 하기 ( caltech 이미지 사용 )
4. 학습된 모델 사용하기
드디어 TF-Slim 실습을 해보도록 하겠습니다.




다운로드 지정한 폴더로 가보겠습니다. TFRecord 포멧 변환이 완료 되었습니다!

train용 TFRecord 5개와 validation용 5개 파일, 분류 클래스가 정의 되어 있는 labels 파일이 생성된 것을 확인할 수 있습니다. 이제 텐소플로우는 학습할 때 원본 이미지를 사용하지 않고 이 TFRecord 포멧 파일을 사용 할 겁니다.
2.1절에서 다운 받았던 flowers 이미지 셋을 가지고 inception_v1 모델로 새롭게 학습시켜 보겠습니다. ( 제 컴퓨터 사양에서 돌아가는 저사양 딥러닝 네트워크 모델입니다. )



1. 윈도우에 Tensorflow GPU 버전 설치하기
2 딥러닝 slim 라이브러리 설치, 학습, 평가하기
3. 내 이미지로 학습 하기 ( caltech 이미지 사용 )
4. 학습된 모델 사용하기
실습은 https://github.com/tensorflow/models/tree/master/research/slim 에 있는 내용을 그대로 따라 진행하지만 내용을 보면 아시겠지만 리눅스 코드로 되어 있습니다. 저희는 Tensorflow를 윈도우 아나콘다에 깔았기 때문에 실행이 안되는 코드들도 있습니다. 이런 것들을 하나씩 고쳐가면서 실습을 하겠습니다.
2.1 딥러닝 slim 라이브러리 설치 및 이미지 셋 다운로드
1) TF-Slim 이미지 모델 라이브러리 다운로드
https://github.com/tensorflow/models 이 곳에 들어 갑니다.

텐소플로우로 구현된 모델들이 다 모여있네요. research 폴더에 들어가 보면 RNN 예제도 있고, 오토엔코더 예제도 보입니다. 이 파일들을 그림에 표시한 버튼들을 눌러 다 다운받아 컴퓨터 적당한 위치에 압축을 풉니다. 따로 인스톨 과정을 거칠 필요는 없고 압축 푼 폴더에서 실습을 진행하면 됩니다.( 저같은 경우는 아래 그림과 같이 D 드라이브에 압축을 풀었습니다. )

압축을 푼 폴더에서 research - slim 폴더 안으로 가보면 위와 같은 파일들을 볼 수 있습니다. 간략히 파일 내용을 소개해 드리겠습니다.
- download_and_conver_data.py : 학습할 이미지 다운 받고 TFRecord 포멧 생성
- train_image_classifier.py : 대상 이미지 학습
- eval_image_cliassifier.py : 학습된 모델 평가(정확도 몇 퍼센트)
- slim_walkthough.ipynb : slim 코드 사용법 설명하는 아이파이썬 노트북 파일
그외 하위 폴더들은 실습을 하면서 알아보도록 하겠습니다.
2) 이미지 데이터 다운로드 및 TFRecord 변환
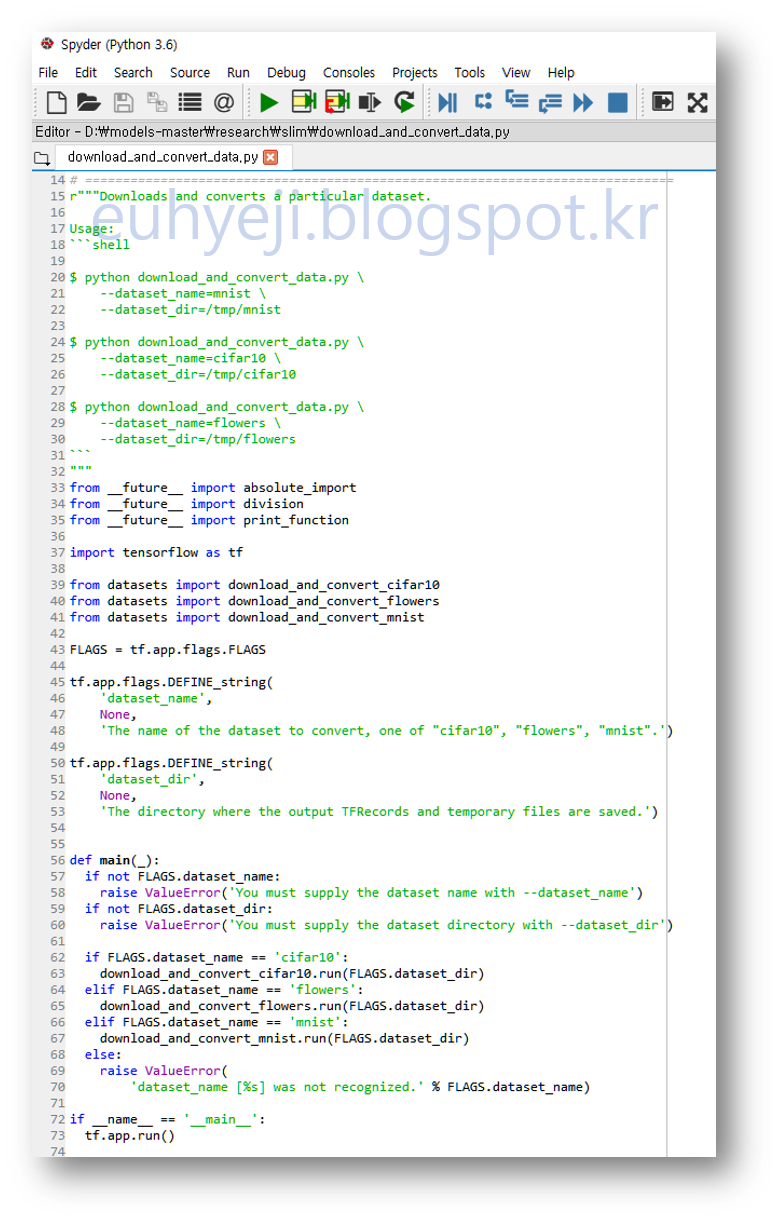
앞에서 소개한 download_and_convert_data.py 의 코드를 열어 보겠습니다. 코드 실행 중 에러 발생시 에러 발생된 코드 라인 넘버가 함께 표시되기 때문에 꼭 아래와 같이 코드 라인이 함께 표시되는 편집기를 사용해 주세요. 컴퓨터에 따로 Python 편집기가 없다면 아나콘다를 설치할 때 함께 설치된 Spyder를 사용하겠습니다.

코드를 한번 훑어 보겠습니다. 17~31 라인을 보면 실행 방법이 잘 나와 있네요. 현재는 cifar10, flowers, mnist 3개의 이미지 셋이 제공되고 있습니다. 실습을 위해 저희는 flowers 이미지 셋을 다운 받아 보겠습니다.
파이썬 코드를 실행하기 전에 datasets 폴더의 download_and_convert_flowers.py를 열어서 210 라인에 있는 코드를 주석 처리(문장 제일 앞에 # 입력하면 됩니다) 하겠습니다. 이유는 이 명령어는 다운 받은 flowers 이미지 셋 원본 파일을 지워버리는 코드인데 나중에 새로운 이미지를 적용하기 위해서는 이미지 셋 폴더 구성이 어떠해야 하는지 확인해야 하기 때문에 지워져서는 안되기 때문입니다.
파이썬 코드를 실행하기 전에 datasets 폴더의 download_and_convert_flowers.py를 열어서 210 라인에 있는 코드를 주석 처리(문장 제일 앞에 # 입력하면 됩니다) 하겠습니다. 이유는 이 명령어는 다운 받은 flowers 이미지 셋 원본 파일을 지워버리는 코드인데 나중에 새로운 이미지를 적용하기 위해서는 이미지 셋 폴더 구성이 어떠해야 하는지 확인해야 하기 때문에 지워져서는 안되기 때문입니다.

주석 처리 한 후 저장을 하고, 아나콘다로 가서 아래 명령어로 파이선 코드를 실행 시켜 보겠습니다. --dataset_dir는 자신이 원하는 저장 폴더를 지정하면 됩니다. 저는 그냥 예제대로 하겠습니다.
python download_and_convert_data.py --dataset_name=flowers --dataset_dir=/tmp/flowers

다운로드 지정한 폴더로 가보겠습니다. TFRecord 포멧 변환이 완료 되었습니다!

2.2 딥러닝 slim 모델 학습하기
이제 딥러닝 모델 학습 실습을 해보겠습니다. 학습 방법은 2가지가 있는데 첫번째는 'Training a model from scratch' 방법입니다. 스크래치가 뭔지 찾아보니 '밑바닥' 이란 뜻이더군요. 즉 완전 새롭게 모델을 만드는 방법입니다. 두번째는 'Fine-tuning a model from an existing checkpoint' 인데 이미 잘 만들어진 모델에 추가 이미지를 학습 시켜 모델을 만드는 방법입니다. 이 두가지 방법에 대해 실습을 진행해 보겠습니다.
1) Trainng a model from scratch
2.1절에서 다운 받았던 flowers 이미지 셋을 가지고 inception_v1 모델로 새롭게 학습시켜 보겠습니다. ( 제 컴퓨터 사양에서 돌아가는 저사양 딥러닝 네트워크 모델입니다. )
python train_image_classifier.py
--train_dir=\tmp\train_inception_v1_flowers_logs # 모델 저장될 폴더
--dataset_name=flowers # 이미지 셋 이름
--dataset_split_name=train # 학습에 사용할 이미지 선택
--dataset_dir=\tmp\flowers # 이미지 셋 위치
--batch_size=16 # 기본 32이나 메모리 부족 에러 발생 -> 16 설정
--model_name=inception_v1 # 사용할 모델 이름
python train_image_classifier.py --train_dir=\tmp\train_inception_v1_flowers_logs --dataset_name=flowers --dataset_split_name=train --dataset_dir=\tmp\flowers --batch_size=16 --model_name=inception_v1
실행 후 저는 아래와 같은 에러가 발생하네요.
 구글링을 해보니 아래와 같이 train_image_classifier.py 코드를 수정해 주면 됩니다.
구글링을 해보니 아래와 같이 train_image_classifier.py 코드를 수정해 주면 됩니다.
 다시 실행을 합니다.
다시 실행을 합니다.



python train_image_classifier.py --train_dir=\tmp\train_inception_v1_flowers_logs --dataset_name=flowers --dataset_split_name=train --dataset_dir=\tmp\flowers --batch_size=16 --model_name=inception_v1

위 명령어 실행 시 아무런 파라미터 변수 설정을 안하고 실행시켰기 때문에 네트워크 기본 값으로 학습이 진행 됩니다. 자세한 파라미터 셋팅 값을 확인하고 싶다면 train_image_classifier.py 파일을 열어보면 알 수 있습니다. 위 화면처럼 step 수가 증가하면서 학습이 되는 것을 볼 수 있습니다. 학습을 중단 시키고 싶을 때는 Ctrl+C 를 누르면 중단됩니다.

모델 저장 위치로 지정한 폴더에 가보면 위와 같이 모델이 생성된 것을 볼 수 있습니다. model.ckpt-숫자 파일이 모델 파일입니다. 이 모델을 텐소플로우에서는 checkpoint라고 부르는 것 같습니다. 나머지는 파일들은... 잘 모르겠습니다^^; 이 위치로 Tensorboard 를 실행하면 다양한 재밌는 정보들도 볼 수 있는데... 그 정보들이 무엇을 의미하는지는... 잘 모릅니다^^;(공부 할게요) 암튼 이렇게 딥러닝 모델 하나를 만들어 보았습니다.
2) Fine-tuning a model from an existing checkpoint
이미 생성되어진 모델을 베이스로 해서 새로운 이미지를 학습하는 방법입니다. 앞선 모델 학습시 inception_v1 모델로 flowers 분류 학습을 해봤으니 비교를 위해 같은 모델로 ImageNet이 미리 학습된 모델을 다운 받겠습니다. 실제 ImageNet top5 89.6% 정확도를 가진 모델입니다.
다운 받았으면 압축을 풀어 inception_v1.ckpt 파일을 \tmp\my_checkpoints 폴더로 복사하세요.
지금 하는 실습에서는 2번의 학습 과정을 실습 할 겁니다. 1번 과정은 다운 받은 모델에서 마지막 layer만 새롭게 학습하는 과정이고, 2번 과정은 1번 학습을 거친 모델을 다시 전체 layer가 학습되도록 하는 과정입니다.
1번 과정 #Fine-tune only the new layers for 1000 steps.
python train_image_classifier.py
--train_dir=\tmp\train_inception_v1_flowers_FineTune_logs
--dataset_name=flowers
--dataset_split_name=train
--dataset_dir=\tmp\flowers
--model_name=inception_v1
--checkpoint_path=\tmp\my_checkpoints/inception_v1.ckpt
--checkpoint_exclude_scopes=InceptionV1/Logits
--trainable_scopes=InceptionV1/Logits
--max_number_of_steps=1000
--batch_size=16
--learning_rate=0.01
--learning_rate_decay_type=fixed
--save_interval_secs=60
--save_summaries_secs=60
--log_every_n_steps=100
--optimizer=rmsprop
--weight_decay=0.00004
--dataset_name=flowers
--dataset_split_name=train
--dataset_dir=\tmp\flowers
--model_name=inception_v1
--checkpoint_path=\tmp\my_checkpoints/inception_v1.ckpt
--checkpoint_exclude_scopes=InceptionV1/Logits
--trainable_scopes=InceptionV1/Logits
--max_number_of_steps=1000
--batch_size=16
--learning_rate=0.01
--learning_rate_decay_type=fixed
--save_interval_secs=60
--save_summaries_secs=60
--log_every_n_steps=100
--optimizer=rmsprop
--weight_decay=0.00004
python train_image_classifier.py --train_dir=\tmp\train_inception_v1_flowers_FineTune_logs --dataset_name=flowers --dataset_split_name=train --dataset_dir=\tmp\flowers --model_name=inception_v1 --checkpoint_path=\tmp\my_checkpoints\inception_v1.ckpt --checkpoint_exclude_scopes=InceptionV1/Logits --trainable_scopes=InceptionV1/Logits --max_number_of_steps=1000 --batch_size=16 --learning_rate=0.01 --learning_rate_decay_type=fixed --save_interval_secs=60 --save_summaries_secs=60 --log_every_n_steps=100 --optimizer=rmsprop --weight_decay=0.00004
파라미터 설정 변수가 상당히 많네요. 그 중 위에 빨간색으로 표시한 파라미터가 마지막 layer만 학습하겠다는 변수입니다. 왜 마지막 layer를 새롭게 학습해야 하냐면 다운받은 모델은 ImageNet class 1001개의 분류를 목적으로 하는 모델인데 반해 지금 우리가 학습할 flowers는 class 5개 분류를 목적으로 하기 때문에 마지막 layer의 기존 1001 분류하던걸 없에고 5개로 분류하게 새롭게 만들어야 하기 때문입니다.

1000 step 후 학습이 완료 되었습니다. 지정한 폴더에 모델이 생성된 것을 확인 할 수 있습니다. 이제 2번 과정인 전체 layer 학습을 진행 하겠습니다.
2번 과정 # Fine-tune all the new layers for 500 steps.
python train_image_classifier.py
--train_dir=\tmp\train_inception_v1_flowers_FineTune_logs\all
--dataset_name=flowers
--dataset_split_name=train
--dataset_dir=\tmp\flowers
--model_name=inception_v1
--checkpoint_path=\tmp\train_inception_v1_flowers_FineTune_logs
--max_number_of_steps=500
--batch_size=16
--learning_rate=0.0001
--learning_rate_decay_type=fixed
--save_interval_secs=60
--save_summaries_secs=60
--log_every_n_steps=10
--optimizer=rmsprop
--weight_decay=0.00004
python train_image_classifier.py --train_dir=\tmp\train_inception_v1_flowers_FineTune_logs\all --dataset_name=flowers --dataset_split_name=train --dataset_dir=\tmp\flowers --model_name=inception_v1 --checkpoint_path=\tmp\train_inception_v1_flowers_FineTune_logs --max_number_of_steps=500 --batch_size=16 --learning_rate=0.0001 --learning_rate_decay_type=fixed --save_interval_secs=60 --save_summaries_secs=60 --log_every_n_steps=10 --optimizer=rmsprop --weight_decay=0.00004
1번 과정과 다른 점은 checkpoint_path로 1번 과정에서 생성된 모델로 지정했다는 점입니다. 그리고 마지막 layer만 학습 한다는 파라미터 변수도 삭제 되었죠.

2번 과정을 거친 모델이 생성 되었습니다.
2.2절 실습에서는 같은 flowers 이미지를 가지고 총 3개의 딥러닝 모델을 학습 시켜 봤습니다. 과연 생성된 모델의 정확도는 얼마일까요??
2.3 딥러닝 slim 모델 평가하기
2.2절에서 학습한 3가지 모델의 종류는 아래와 같고, 순서대로 평가 해 보겠습니다.


1번 모델 : Flowers로부터 새롭게 만든 모델
2번 모델 : 이미 잘 만들어진 모델로부터 Flowers로 마지막 layer만 학습해 만든 모델
3번 모델 : 2번에서 만든 모델로부터 전체 layer를 학습해 만든 모델
아나콘다에서 slim 폴더로 이동한 후 아래 명령어로 1번 모델을 평가해보겠습니다.
python eval_image_classifier.py
--alsologtostderr
--checkpoint_path=\tmp\train_inception_v1_flowers_logs\
--dataset_dir=\tmp\flowers
--dataset_name=flowers
--dataset_split_name=validation
--model_name=inception_v1
python eval_image_classifier.py –alsologtostderr --checkpoint_path=\tmp\train_inception_v1_flowers_logs\ --dataset_dir=\tmp\flowers --dataset_name=flowers --dataset_split_name=validation --model_name=inception_v1
eval_image_classifier.py 파일이 --checkpoint_path 로 지정된 폴더의 모델을 평가하는 명령어 입니다.
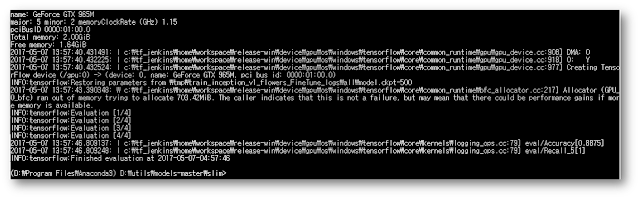
모델 평가 결과를 확인해 보겠습니다.

마지막 부분에 보면 eval/Recall_5[1] 이라고 나온 부분은 ImageNet 처럼 모델에서 예측 확률이 가장 높게 나온 5개 class 중에 하나가 맞으면 맞다고 보는 정확도 측정 방법입니다. [ ] 안에 있는 값이 예측 정확도인데 무려 1 -> 100% 라는 말입니다! Flowers 이미지는 원래 5개 중에서 하나를 맞추는 것이기 때문에 당연히 100% 예측 정확도가 나옵니다. 그 앞 줄에 있는 eval/Accuracy[0.535] 에 있는 값이 실 예측 정확도 입니다. 53.5%가 나오는 것으로 평가 됩니다.
다음은 2번 모델을 평가하겠습니다.
2번 모델의 위치만 --checkpoint_path에 지정해주고 실행시킵니다.
python eval_image_classifier.py
--alsologtostderr
--checkpoint_path=\tmp\train_inception_v1_flowers_FineTune_logs\
--dataset_dir=\tmp\flowers
--dataset_name=flowers
--dataset_split_name=validation
--model_name=inception_v1
python eval_image_classifier.py –alsologtostderr --checkpoint_path=\tmp\train_inception_v1_flowers_FineTune_logs\ --dataset_dir=\tmp\flowers --dataset_name=flowers --dataset_split_name=validation --model_name=inception_v1

86% 분류 예측 정확도가 나옵니다.
3번 모델을 평가 하겠습니다.
python eval_image_classifier.py
--alsologtostderr
--checkpoint_path=\tmp\train_inception_v1_flowers_FineTune_logs\all\
--dataset_dir=\tmp\flowers
--dataset_name=flowers
--dataset_split_name=validation
--model_name=inception_v1
python eval_image_classifier.py –alsologtostderr --checkpoint_path=\tmp\train_inception_v1_flowers_FineTune_logs\all\ --dataset_dir=\tmp\flowers --dataset_name=flowers --dataset_split_name=validation --model_name=inception_v1

3번 모델은 88.75%의 분류 예측 정확도를 보였습니다.
정리
Steps
|
학습 시간
|
모델 정확도
| |
1번 모델
|
5616
|
약 39 분
|
53.5 %
|
2번 모델
|
1000
|
약 2 분
|
86 %
|
3번 모델
|
500
|
약 3 분
|
88.75 %
|
이미지 분류 학습에 있어서는 기존 잘 학습된 모델을 활용해서 그 위에 분류하고 싶은 추가적인 이미지를 학습 하는 것이 효과적이라는 것을 알 수 있습니다. 학습 시간을 단축하면서도 높은 모델 정확도를 얻을 수 있기 때문입니다.
지금까지 Tensorflow slim (TF-Slim)을 이용한 딥러닝 이미지 분류기 모델의 이미지 준비부터 모델 학습, 평가 까지 실습을 다 해보았습니다.
다음에는 예제에 포함되어 있지 않은 Caltech 이미지(257 label class)를 어떻게 TF-Slim을 사용해서 딥러닝 모델을 만드는지 실습해 보도록 하겠습니다.













{kind=link}
안녕하세요 꼭 gpu가 있는 컴퓨터에서만 실행 가능한 코드인가요?
답글삭제CPU도 가능한데 GPU보다 약 20배는 느릴걸요
삭제작성자가 댓글을 삭제했습니다.
답글삭제안녕하세요 덕분에 딥러닝 공부를 쉽게 접근하였네요
답글삭제감사합니다.
작성자가 댓글을 삭제했습니다.
답글삭제다시 공부하고자 처음부터 따라하고 있는데, 1번과정 fine tune에서 아래와 같은 현상이 발생하는데, 원인을 모르겠습니다.
답글삭제Fatal Python error: Segmentation fault
Current thread 0x00002134 (most recent call first):
File "C:\Users\Leon\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\lib\io\file_io.py", line 384 in get_matching_files_v2
File "C:\Users\Leon\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\lib\io\file_io.py", line 363 in get_matching_files
File "C:\Users\Leon\Anaconda3\envs\tensorflow\lib\site-packages\tf_slim\data\parallel_reader.py", line 315 in get_data_files
File "C:\Users\Leon\Anaconda3\envs\tensorflow\lib\site-packages\tf_slim\data\parallel_reader.py", line 242 in parallel_read
File "C:\Users\Leon\Anaconda3\envs\tensorflow\lib\site-packages\tf_slim\data\dataset_data_provider.py", line 99 in __init__
File "train_image_classifier.py", line 466 in main
File "C:\Users\Leon\Anaconda3\envs\tensorflow\lib\site-packages\absl\app.py", line 251 in _run_main
File "C:\Users\Leon\Anaconda3\envs\tensorflow\lib\site-packages\absl\app.py", line 303 in run
File "C:\Users\Leon\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\python\platform\app.py", line 40 in run
File "train_image_classifier.py", line 613 in
도움 부탁드립니다