
*Tensorflow 1.9 버전 튜토리얼
1. 윈도우에 Tensorflow GPU 버전 설치하기
2 딥러닝 slim 라이브러리 설치, 학습, 평가하기
3. 내 이미지로 학습 하기 ( caltech 이미지 사용 )
4. 학습된 모델 사용하기
* Tensorflow 1.1 업그레이드 이후 Slim을 사용하기 위한 튜토리얼 리비전 입니다.
1. 윈도우에 Tensorflow GPU 버전 설치하기
2.1 딥러닝 slim 라이브러리 설치 및 이미지 셋 다운로드
2.2 딥러닝 모델 학습하기
2.3 딥러닝 모델 평가하기
3. 내 이미지로 학습 하기 ( caltech 이미지 사용 )
4. 학습된 모델 사용하기
이제 딥러닝 모델 학습 실습을 해보겠습니다. 학습 방법은 2가지가 있는데 첫번째는 'Training a model from scratch' 방법입니다. 스크래치가 뭔지 찾아보니 '밑바닥' 이란 뜻이더군요. 즉 완전 새롭게 모델을 만드는 방법입니다. 두번째는 'Fine-tuning a model from an existing checkpoint' 인데 이미 잘 만들어진 모델에 추가 이미지를 학습 시켜 모델을 만드는 방법입니다. 이 두가지 방법에 대해 실습을 진행해 보겠습니다.
지난 시간에 다운 받았던 flowers 이미지 셋을 가지고 inception_v1 모델로 새롭게 학습시켜 보겠습니다. ( 제 컴퓨터 사양에서 돌아가는 저사양 딥러닝 네트워크 모델입니다. )


이미 생성되어진 모델을 베이스로 해서 새로운 이미지를 학습하는 방법입니다. 앞선 모델 학습시 inception_v1 모델로 flowers 분류 학습을 해봤으니 비교를 위해 같은 모델로 ImageNet이 미리 학습된 모델을 다운 받겠습니다. 실제 ImageNet top5 89.6% 정확도를 가진 모델입니다.
--train_dir=\tmp\train_inception_v1_flowers_FineTune_logs
--dataset_name=flowers
--dataset_split_name=train
--dataset_dir=\tmp\flowers
--model_name=inception_v1
--checkpoint_path=\tmp\my_checkpoints/inception_v1.ckpt
--checkpoint_exclude_scopes=InceptionV1/Logits
--trainable_scopes=InceptionV1/Logits
--max_number_of_steps=1000
--batch_size=16
--learning_rate=0.01
--learning_rate_decay_type=fixed
--save_interval_secs=60
--save_summaries_secs=60
--log_every_n_steps=100
--optimizer=rmsprop
--weight_decay=0.00004
파라미터 설정 변수가 상당히 많네요. 그 중 위에 빨간색으로 표시한 파라미터가 마지막 layer만 학습하겠다는 변수입니다. 왜 마지막 layer를 새롭게 학습해야 하냐면 다운받은 모델은 ImageNet class 1001개의 분류를 목적으로 하는 모델인데 반해 지금 우리가 학습할 flowers는 class 5개 분류를 목적으로 하기 때문에 마지막 layer의 기존 1001 분류하던걸 없에고 5개로 분류하게 새롭게 만들어야 하기 때문입니다.

1000 step 후 학습이 완료 되었습니다. 지정한 폴더에 모델이 생성된 것을 확인 할 수 있습니다. 이제 2번 과정인 전체 layer 학습을 진행 하겠습니다.
2번 과정 # Fine-tune all the new layers for 500 steps.
1번 과정과 다른 점은 checkpoint_path로 1번 과정에서 생성된 모델로 지정했다는 점입니다. 그리고 마지막 layer만 학습 한다는 파라미터 변수도 삭제 되었죠.

오늘 실습에서 같은 flowers 이미지를 가지고 총 3개의 딥러닝 모델을 학습 시켜 봤습니다. 과연 생성된 모델의 정확도는 얼마일까요?? 다음 포스팅에서 모델 평가(Evaluation) 실습을 하겠습니다.
1. 윈도우에 Tensorflow GPU 버전 설치하기
2 딥러닝 slim 라이브러리 설치, 학습, 평가하기
3. 내 이미지로 학습 하기 ( caltech 이미지 사용 )
4. 학습된 모델 사용하기
* Tensorflow 1.1 업그레이드 이후 Slim을 사용하기 위한 튜토리얼 리비전 입니다.
1. 윈도우에 Tensorflow GPU 버전 설치하기
2.1 딥러닝 slim 라이브러리 설치 및 이미지 셋 다운로드
2.2 딥러닝 모델 학습하기
2.3 딥러닝 모델 평가하기
3. 내 이미지로 학습 하기 ( caltech 이미지 사용 )
4. 학습된 모델 사용하기
이제 딥러닝 모델 학습 실습을 해보겠습니다. 학습 방법은 2가지가 있는데 첫번째는 'Training a model from scratch' 방법입니다. 스크래치가 뭔지 찾아보니 '밑바닥' 이란 뜻이더군요. 즉 완전 새롭게 모델을 만드는 방법입니다. 두번째는 'Fine-tuning a model from an existing checkpoint' 인데 이미 잘 만들어진 모델에 추가 이미지를 학습 시켜 모델을 만드는 방법입니다. 이 두가지 방법에 대해 실습을 진행해 보겠습니다.
1) Trainng a model from scratch
지난 시간에 다운 받았던 flowers 이미지 셋을 가지고 inception_v1 모델로 새롭게 학습시켜 보겠습니다. ( 제 컴퓨터 사양에서 돌아가는 저사양 딥러닝 네트워크 모델입니다. )
python train_image_classifier.py
--train_dir=\tmp\train_inception_v1_flowers_logs # 모델 저장될 폴더
--dataset_name=flowers # 이미지 셋 이름
--dataset_split_name=train # 학습에 사용할 이미지 선택
--dataset_dir=\tmp\flowers # 이미지 셋 위치
--batch_size=16 # 기본 32이나 메모리 부족 에러 발생 -> 16 설정
--model_name=inception_v1 # 사용할 모델 이름
python train_image_classifier.py --train_dir=\tmp\train_inception_v1_flowers_logs --dataset_name=flowers --dataset_split_name=train --dataset_dir=\tmp\flowers --batch_size=16 --model_name=inception_v1
아나콘다에서 slim 폴더로 이동 후 위 명령어를 실행시키면 여지없이 에러가 발생됩니다.
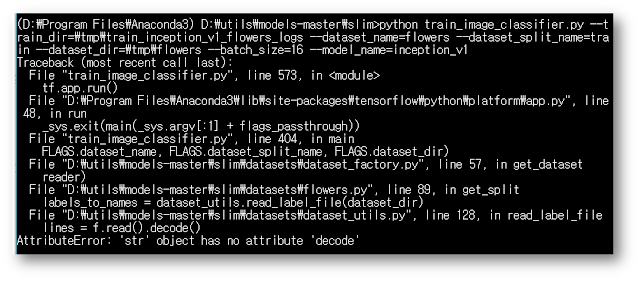 dataset_utils.py 파일 128번 라인에서 에러가 발생했는데 Spyder로 해당 파일을 열어보면 127번 라인에서 "with tf.gfile.Open(labels_filename, 'r') as f:" 를 "with tf.gfile.Open(labels_filename, 'rb') as f:" 로 수정하면 해당 에러가 해결됩니다.
dataset_utils.py 파일 128번 라인에서 에러가 발생했는데 Spyder로 해당 파일을 열어보면 127번 라인에서 "with tf.gfile.Open(labels_filename, 'r') as f:" 를 "with tf.gfile.Open(labels_filename, 'rb') as f:" 로 수정하면 해당 에러가 해결됩니다.



python train_image_classifier.py --train_dir=\tmp\train_inception_v1_flowers_logs --dataset_name=flowers --dataset_split_name=train --dataset_dir=\tmp\flowers --batch_size=16 --model_name=inception_v1
다시 실행 시키면 다행히 아무 에러 없이 잘 실행됩니다.

위 명령어 실행 시 아무런 파라미터 변수 설정을 안하고 실행시켰기 때문에 네트워크 기본 값으로 학습이 진행 됩니다. 자세한 파라미터 셋팅 값을 확인하고 싶다면 train_image_classifier.py 파일을 열어보면 알 수 있습니다. 위 화면처럼 step 수가 증가하면서 학습이 되는 것을 볼 수 있습니다. 학습을 중단 시키고 싶을 때는 Ctrl+C 를 누르면 중단됩니다.

모델 저장 위치로 지정한 폴더에 가보면 위와 같이 모델이 생성된 것을 볼 수 있습니다. model.ckpt-숫자 파일이 모델 파일입니다. 이 모델을 텐소플로우에서는 checkpoint라고 부르는 것 같습니다. 나머지는 파일들은... 잘 모르겠습니다^^; 이 위치로 Tensorboard 를 실행하면 다양한 재밌는 정보들도 볼 수 있는데... 그 정보들이 무엇을 의미하는지는... 잘 모릅니다^^;(공부 할게요) 암튼 이렇게 딥러닝 모델 하나를 만들어 보았습니다.
2) Fine-tuning a model from an existing checkpoint
다운 받았으면 압축을 풀어 inception_v1.ckpt 파일을 \tmp\my_checkpoints 폴더로 복사하세요.
지금 하는 실습에서는 2번의 학습 과정을 실습 할 겁니다. 1번 과정은 다운 받은 모델에서 마지막 layer만 새롭게 학습하는 과정이고, 2번 과정은 1번 학습을 거친 모델을 다시 전체 layer가 학습되도록 하는 과정입니다.
1번 과정 #Fine-tune only the new layers for 1000 steps.
python train_image_classifier.py--train_dir=\tmp\train_inception_v1_flowers_FineTune_logs
--dataset_name=flowers
--dataset_split_name=train
--dataset_dir=\tmp\flowers
--model_name=inception_v1
--checkpoint_path=\tmp\my_checkpoints/inception_v1.ckpt
--checkpoint_exclude_scopes=InceptionV1/Logits
--trainable_scopes=InceptionV1/Logits
--max_number_of_steps=1000
--batch_size=16
--learning_rate=0.01
--learning_rate_decay_type=fixed
--save_interval_secs=60
--save_summaries_secs=60
--log_every_n_steps=100
--optimizer=rmsprop
--weight_decay=0.00004
python train_image_classifier.py --train_dir=\tmp\train_inception_v1_flowers_FineTune_logs --dataset_name=flowers --dataset_split_name=train --dataset_dir=\tmp\flowers --model_name=inception_v1 --checkpoint_path=\tmp\my_checkpoints\inception_v1.ckpt --checkpoint_exclude_scopes=InceptionV1/Logits --trainable_scopes=InceptionV1/Logits --max_number_of_steps=1000 --batch_size=16 --learning_rate=0.01 --learning_rate_decay_type=fixed --save_interval_secs=60 --save_summaries_secs=60 --log_every_n_steps=100 --optimizer=rmsprop --weight_decay=0.00004

2번 과정 # Fine-tune all the new layers for 500 steps.
python train_image_classifier.py
--train_dir=\tmp\train_inception_v1_flowers_FineTune_logs\all
--dataset_name=flowers
--dataset_split_name=train
--dataset_dir=\tmp\flowers
--model_name=inception_v1
--checkpoint_path=\tmp\train_inception_v1_flowers_FineTune_logs
--max_number_of_steps=500
--batch_size=16
--learning_rate=0.0001
--learning_rate_decay_type=fixed
--save_interval_secs=60
--save_summaries_secs=60
--log_every_n_steps=10
--optimizer=rmsprop
--weight_decay=0.00004
python train_image_classifier.py --train_dir=\tmp\train_inception_v1_flowers_FineTune_logs\all --dataset_name=flowers --dataset_split_name=train --dataset_dir=\tmp\flowers --model_name=inception_v1 --checkpoint_path=\tmp\train_inception_v1_flowers_FineTune_logs --max_number_of_steps=500 --batch_size=16 --learning_rate=0.0001 --learning_rate_decay_type=fixed --save_interval_secs=60 --save_summaries_secs=60 --log_every_n_steps=10 --optimizer=rmsprop --weight_decay=0.00004

2번 과정을 거친 모델이 생성 되었습니다.
오늘 실습에서 같은 flowers 이미지를 가지고 총 3개의 딥러닝 모델을 학습 시켜 봤습니다. 과연 생성된 모델의 정확도는 얼마일까요?? 다음 포스팅에서 모델 평가(Evaluation) 실습을 하겠습니다.
*질문은 댓글로 주세요.











{kind=link}
{kind=link}
안녕하세요. 수정해서 올려주신 tf 1.1용 포스트덕분에 2.1절 flower 영상 변환까지는 성공하였습니다. 그런데, 2.2절에서 dataset_utils.py 파일 128번 라인을 수정하고,python train_image_classifier.py --train_dir=\tmp\train_inception_v1_flowers_logs --dataset_name=flowers --dataset_split_name=train --dataset_dir=\tmp\flowers --batch_size=16 --model_name=inception_v1을 실행하면 tensorflow:Error reported to Coordinator: a bytes-like object is required, not 'str' 에러가 납니다. 뭐가 잘못된걸가요? 미리 감사드립니다.
답글삭제안녕하세요~ 제 코드에서는 에러가 나지 않아서 원인을 알 수 없네요. 에러가 나는 출력 화면 글을 복사해서 한번 붙여봐 주시겠어요? 해당 에러가 어느 라인에서 났는지 보셔야 할거고... 그다음 저 키워드로 구글링을 해보는 수 밖에는 없을거 같네요.
삭제안녕하세요, 위에 올려주신 내용에 대해서 학습 진행중인데요. 오류가 나는 부분이 있는데 혹시나 하는 마음에 문의드립니다.
답글삭제(C:\Anaconda3) c:\utils\models-master\slim>python train_image_classifier.py --train_dir=\tmp\train_inception_v1_flowers_logs --dataset_name=flowers --dataset_split_name=train --dataset_dir=\tmp\flowers --batch_size=16 --model_name=inception_v1
Traceback (most recent call last):
File "train_image_classifier.py", line 573, in
tf.app.run()
File "C:\Anaconda3\lib\site-packages\tensorflow\python\platform\app.py", line 43, in run
sys.exit(main(sys.argv[:1] + flags_passthrough))
File "train_image_classifier.py", line 472, in main
clones = model_deploy.create_clones(deploy_config, clone_fn, [batch_queue])
File "c:\utils\models-master\slim\deployment\model_deploy.py", line 195, in create_clones
outputs = model_fn(*args, **kwargs)
File "train_image_classifier.py", line 455, in clone_fn
logits, end_points = network_fn(images)
File "c:\utils\models-master\slim\nets\nets_factory.py", line 105, in network_fn
return func(images, num_classes, is_training=is_training)
File "c:\utils\models-master\slim\nets\inception_v1.py", line 290, in inception_v1
net, end_points = inception_v1_base(inputs, scope=scope)
File "c:\utils\models-master\slim\nets\inception_v1.py", line 96, in inception_v1_base
net = tf.concat(axis=3, values=[branch_0, branch_1, branch_2, branch_3])
TypeError: concat() got an unexpected keyword argument 'axis'
inception_v1.py 파일 내에 코드 중 #net = tf.concat(axis=3, values=[branch_0, branch_1, branch_2, branch_3])을 net = tf.concat(3, values=[branch_0, branch_1, branch_2, branch_3])으로 변경으로 해결했습니다. 감사합니다.
삭제안녕하세요! 자세하게 글 올려주셔서 정말 감사합니다. 1번 과정을 하고 있었는데요 python3 train_image_classifier.py --train_dir=\tmp\train_inception_v1_flowers_logs --dataset_name=flowers --dataset_split_name=train --dataset_dir=/home/nicehe74/flowers --batch_size=16 --model_name=inception_v1 라고 명령어를 치니
답글삭제INFO:tensorflow:global step 14560: loss = 0.4729 (0.161 sec/step) 이런식으로 뜨며 잘 돌아가다가 step이 끝나지 않아서 중간에 멈췄는데 아래와 같은 에러가 뜨며 아무것도 생성되지 않았네요..ㅠㅠ 혹시 좀 도움을 구할 수 있을까요?
Traceback (most recent call last):
File "train_image_classifier.py", line 573, in
tf.app.run()
File "/usr/local/lib/python3.4/dist-packages/tensorflow/python/platform/app.py", line 48, in run
_sys.exit(main(_sys.argv[:1] + flags_passthrough))
File "train_image_classifier.py", line 569, in main
sync_optimizer=optimizer if FLAGS.sync_replicas else None)
File "/usr/local/lib/python3.4/dist-packages/tensorflow/contrib/slim/python/slim/learning.py", line 749, in train
sess, train_op, global_step, train_step_kwargs)
File "/usr/local/lib/python3.4/dist-packages/tensorflow/contrib/slim/python/slim/learning.py", line 488, in train_step
run_metadata=run_metadata)
File "/usr/local/lib/python3.4/dist-packages/tensorflow/python/client/session.py", line 789, in run
run_metadata_ptr)
File "/usr/local/lib/python3.4/dist-packages/tensorflow/python/client/session.py", line 997, in _run
feed_dict_string, options, run_metadata)
File "/usr/local/lib/python3.4/dist-packages/tensorflow/python/client/session.py", line 1132, in _do_run
target_list, options, run_metadata)
File "/usr/local/lib/python3.4/dist-packages/tensorflow/python/client/session.py", line 1139, in _do_call
return fn(*args)
File "/usr/local/lib/python3.4/dist-packages/tensorflow/python/client/session.py", line 1121, in _run_fn
status, run_metadata)
중간에 멈추지 마시고 해당 폴더에 파일 생성될때 까지 학습을 시켜 주세요~^^
삭제네 감사합니다 다시돌리고있습니당! 엄청나게 오랫동안 돌아가네요ㅋㅋㅋ.. 근데 질문이 있는데요, inception모델에 원래 flower을 분류할 수 없었는데, 이렇게 학습시킴으로 flower 또한 분류할 수 있도록 inception모델이 수정된건가요? 그리고 2번학습방법은 flower을 분류하는 class를 추가하는 건가요?
삭제원래 inception 모델은 Imagenet 1001 클래스에 대한 분류를 하는 모델인데요. flower 5가지 클래스로 다시 학습을 시키는 거라 기존 1001 클래스는 사라지고 5개에 대한 분류만 가능한 모델로 만들어져요.
삭제안녕하세요 덕분에 slim을 잘 배우고 있습니다!!
답글삭제혹시gpu가 아니라 cpu를 사용하면 문제가 발생할 수 있을까요?
물론 tensorflow는 cpu버전을 설치하였습니다.
혹시 에러가 궁금하실까 하여 아래에 내용을 복사하여 남김니다
---------------------------------------------------------------------------------
ERROR:tensorflow:==================================
Object was never used (type ):
If you want to mark it as used call its "mark_used()" method.
It was originally created here:
['File "train_image_classifier.py", line 573, in \n tf.app.run()', 'File "C:\\Users\\USER\\Anaconda3\\envs\\tensorflow\\lib\\site-packages\\tensorflow\\python\\platform\\app.py", line 48, in run\n _sys.exit(main(_sys.argv[:1] + flags_passthrough))', 'File "train_image_classifier.py", line 569, in main\n sync_optimizer=optimizer if FLAGS.sync_replicas else None)', 'File "C:\\Users\\USER\\Anaconda3\\envs\\tensorflow\\lib\\site-packages\\tensorflow\\contrib\\slim\\python\\slim\\learning.py", line 655, in train\n ready_op = tf_variables.report_uninitialized_variables()', 'File "C:\\Users\\USER\\Anaconda3\\envs\\tensorflow\\lib\\site-packages\\tensorflow\\python\\util\\tf_should_use.py", line 170, in wrapped\n return _add_should_use_warning(fn(*args, **kwargs))', 'File "C:\\Users\\USER\\Anaconda3\\envs\\tensorflow\\lib\\site-packages\\tensorflow\\python\\util\\tf_should_use.py", line 139, in _add_should_use_warning\n wrapped = TFShouldUseWarningWrapper(x)', 'File "C:\\Users\\USER\\Anaconda3\\envs\\tensorflow\\lib\\site-packages\\tensorflow\\python\\util\\tf_should_use.py", line 96, in __init__\n stack = [s.strip() for s in traceback.format_stack()]']
==================================
작성자가 댓글을 삭제했습니다.
삭제안녕하세요 질문을 남겼던 사람입니다. 자문 자답이 되어 버렸지만 cpu로 실행을 할때는 train_image_classifier.py의 40번째 줄을 약간 변경해야 하는 것으로 보입니다.
삭제cpu 버전과 gpu 버전에 따라서 train_image_classifier.py 에서 40 번째 라인의 tf.app.flags.DEFINE_boolean('clone_on_cpu',False,'Use CPUs to deploy clones.') 이 부분에서 False를 True로 바꾸어 줘야 CPU버전에서는 동작합니다.
tf.app.flags.DEFINE_boolean('clone_on_cpu',False,'Use CPUs to deploy clones.')
->tf.app.flags.DEFINE_boolean('clone_on_cpu',True,'Use CPUs to deploy clones.')
다른 분들에게 참고가 되었으면 좋겠습니다.
계속해서 글 잘 보겠습니다. 감사합니다~
좋은 답변 감사드립니다!
삭제뭔가 에러가 나는데 아직까지 잘모르겠네요.
답글삭제첫번째 방법인
python train_image_classifier.py --train_dir=\tmp\train_inception_v1_flowers_logs --dataset_name=flowers --dataset_split_name=train --dataset_dir=\tmp\flowers --batch_size=16 --model_name=
실행했을때
ValueError: Name of network unknown
이라는 에러가 나옵니다.
slim\nets\nets_factory.py에서 에러가 났다고 나와서
소스를 보니 networks_map이라는 배열이있고 이 안에있는 네트워크 값이 아닌 다른 값이 넘어와서 에러가 나는것같은데.. 이걸 어떻게 찾아서 해결해야될지 모르겠네요..
networks_map = {'alexnet_v2': alexnet.alexnet_v2,
삭제'cifarnet': cifarnet.cifarnet,
'overfeat': overfeat.overfeat,
'vgg_a': vgg.vgg_a,
'vgg_16': vgg.vgg_16,
'vgg_19': vgg.vgg_19,
'inception_v1': inception.inception_v1,
'inception_v2': inception.inception_v2,
'inception_v3': inception.inception_v3,
'inception_v4': inception.inception_v4,
'inception_resnet_v2': inception.inception_resnet_v2,
'lenet': lenet.lenet,
'resnet_v1_50': resnet_v1.resnet_v1_50,
'resnet_v1_101': resnet_v1.resnet_v1_101,
'resnet_v1_152': resnet_v1.resnet_v1_152,
'resnet_v1_200': resnet_v1.resnet_v1_200,
'resnet_v2_50': resnet_v2.resnet_v2_50,
'resnet_v2_101': resnet_v2.resnet_v2_101,
'resnet_v2_152': resnet_v2.resnet_v2_152,
'resnet_v2_200': resnet_v2.resnet_v2_200,
'mobilenet': mobilenet.mobilenet,
'mobilenetdet': mobilenetdet.mobilenet
}
이 네트워크 뜻하는게 뭘까요..?
작성자가 댓글을 삭제했습니다.
답글삭제작성자가 댓글을 삭제했습니다.
답글삭제안녕하세요 혹시 max number step이 아닌 일반 training step은 어떤식으로 적용해야 할까요? .
답글삭제계속적으로 train_image_classifier.py 돌리고 싶은데 max number step 을 수정하지 않는 방법을 알고 싶습니다.
혹시 알고 계신가요?
max number step 값을 충분히 크게 주고 계속 학습시키면 되지 않을까요? 중간에 중단시켜도 Fine Tuning으로 최근 모델 다시 읽어와 재학습 시켜도 되니까요.
삭제Inception 네트워크의 경우 블로그대로 저의 dataset을 fine-tuning에 잘썻습니다.
답글삭제다만, mobilenet 의 경우 fine-tuning 에 대한 정보가 너무 없네요.
Checkpoint dir을 잘 작성하여도
ValueError: The passed save_path is not a valid checkpoint: /tmp/mobilenet_v1/checkpoints//mobilenet_v2_1.0_224.ckpt
와 같은 에러가 발생합니다.
slim에 있는 train_image_classifier.py 는 오직 inception에서만 작동하나요?
"checkpoints//mobilenet_v2_1.0_224.ckpt" 여기에 슬러시가 두개 있어서 에러난 것은 아닌지...
삭제어떤 네트워크던지 잘 돌아가게 되어 있습니다. 다만..
--checkpoint_exclude_scopes=InceptionV1/Logits
--trainable_scopes=InceptionV1/Logits
이런 부분 설정을 해줘야 하는데 네트워크마다 위에 해당하는 이름들이 달라서 이거 설정만 잘 해주면 모두 잘 돌아갑니다.