
*Tensorflow 1.9 버전 튜토리얼
1. 윈도우에 Tensorflow GPU 버전 설치하기
2 딥러닝 slim 라이브러리 설치, 학습, 평가하기
3. 내 이미지로 학습 하기 ( caltech 이미지 사용 )
4. 학습된 모델 사용하기
* Tensorflow 1.1 업그레이드 이후 Slim을 사용하기 위한 튜토리얼 리비전 입니다.
1. 윈도우에 Tensorflow GPU 버전 설치하기
2.1 딥러닝 slim 라이브러리 설치 및 이미지 셋 다운로드
2.2 딥러닝 모델 학습하기
2.3 딥러닝 모델 평가하기
3. 내 이미지로 학습 하기 ( caltech 이미지 사용 )
4. 학습된 모델 사용하기
드디어 TF-Slim 실습을 해보도록 하겠습니다.









1. 윈도우에 Tensorflow GPU 버전 설치하기
2 딥러닝 slim 라이브러리 설치, 학습, 평가하기
3. 내 이미지로 학습 하기 ( caltech 이미지 사용 )
4. 학습된 모델 사용하기
* Tensorflow 1.1 업그레이드 이후 Slim을 사용하기 위한 튜토리얼 리비전 입니다.
1. 윈도우에 Tensorflow GPU 버전 설치하기
2.1 딥러닝 slim 라이브러리 설치 및 이미지 셋 다운로드
2.2 딥러닝 모델 학습하기
2.3 딥러닝 모델 평가하기
3. 내 이미지로 학습 하기 ( caltech 이미지 사용 )
4. 학습된 모델 사용하기
5. Python Tkinter GUI 응용 프로그램 만들기
실습은 https://github.com/tensorflow/models/tree/master/slim 에 있는 내용을 그대로 따라 진행하지만 내용을 보면 아시겠지만 리눅스 코드로 되어 있습니다. 저희는 Tensorflow를 윈도우 아나콘다에 깔았기 때문에 실행이 안되는 코드들도 있습니다. 그리고 실습에 사용되는 TF-Slim Python 코드가 Python2 로 작성되어 있어 Python3으로 설치한 저희의 Tensorflow에서는 코드 실행시 에러가 발생되게 됩니다. 이런 것들도 하나씩 하나씩 고쳐보도록 하겠습니다.
1) TF-Slim 이미지 모델 라이브러리 다운로드
https://github.com/tensorflow/models 이 곳에 들어 갑니다.

텐소플로우로 구현된 모델들이 다 모여있네요. RNN 예제도 있고, 오토엔코더 예제도 보입니다. 이 파일들을 그림에 표시한 버튼들을 눌러 다 다운받아 컴퓨터 적당한 위치에 압축을 풉니다. 따로 인스톨 과정을 거칠 필요는 없고 압축 푼 폴더에서 실습을 진행하면 됩니다.

압축을 푼 폴더에서 slim 폴더 안으로 가보면 위와 같은 파일들을 볼 수 있습니다. 간략히 파일 내용을 소개해 드리겠습니다.
- download_and_conver_data.py : 학습할 이미지 다운 받고 TFRecord 포멧 생성
- train_image_classifier.py : 대상 이미지 학습
- eval_image_cliassifier.py : 학습된 모델 평가(정확도 몇 퍼센트)
- slim_walkthough.ipynb : slim 코드 사용법 설명하는 아이파이썬 노트북 파일
그외 하위 폴더들은 실습을 하면서 알아보도록 하겠습니다.
이제 아나콘다를 실행시키겠습니다. 한가지 팁을 말씀 드리자면 slim 폴더 위에 마우스를 위치시키고 Shift + 오른쪽 마우스 키를 누르면 아래와 같이 뜨는데 '여기서 명령 창 열기'를 클릭하면 해당 폴더 경로의 커멘드 창이 바로 뜹니다.

2) 이미지 데이터 다운로드 및 TFRecord 변환
앞에서 소개한 download_and_convert_data.py 의 코드를 열어 보겠습니다. 코드 실행 중 에러 발생시 에러 발생된 코드 라인 넘버가 함께 표시되기 때문에 꼭 아래와 같이 코드 라인이 함께 표시되는 편집기를 사용해 주세요. 컴퓨터에 따로 Python 편집기가 없다면 아나콘다를 설치할 때 함께 설치된 Spyder를 사용하겠습니다.

코드를 한번 훑어 보겠습니다. 17~31 라인을 보면 실행 방법이 잘 나와 있네요. 현재는 cifar10, flowers, mnist 3개의 이미지 셋이 제공되고 있습니다. 실습을 위해 저희는 flowers 이미지 셋을 다운 받아 보겠습니다. 파이썬 코드를 실행하기 전에 datasets 폴더의 download_and_convert_flowers.py를 열어서 210 라인에 있는 코드를 주석 처리(문장 제일 앞에 # 입력하면 됩니다) 하겠습니다. 이유는 이 명령어는 다운 받은 flowers 이미지 셋 원본 파일을 지워버리는 코드인데 나중에 새로운 이미지를 적용하기 위해서는 이미지 셋 폴더 구성이 어떠해야 하는지 확인해야 하기 때문에 지워져서는 안되기 때문입니다.

주석 처리 한 후 저장을 하고, 아나콘다로 가서 아래 명령어로 파이선 코드를 실행 시켜 보겠습니다. --dataset_dir는 자신이 원하는 저장 폴더를 지정하면 됩니다. 저는 그냥 예제대로 하겠습니다.
python download_and_convert_data.py --dataset_name=flowers --dataset_dir=/tmp/flowers
아... 바로 에러가 나네요.

datasets 폴더의 download_and_convert_cifar10.py 파일의 29번 라인에서 cPickle 이라는 모듈이 없다고 에러가 났습니다. Python3 에서는 cPickle 대신 _pickle 을 사용한다고 하네요(구글링 하면 다 나와요). 아래와 같이 Spyder로 파일을 열어 29번 라인을 수정하고 저장 하겠습니다.
import _pickle as cPickle #import cPickle

다시 에러가 났던 코드를 실행해 보겠습니다.
python download_and_convert_data.py --dataset_name=flowers --dataset_dir=/tmp/flowers
이번에는 flowers 이미지 셋 압축파일은 잘 다운 받았는데... Tensorflow 0.12 버전에는 없던 에러가 발생했네요.
 "UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 0: invalid start byte" 이라는 에러인데 "download_and_convert_flowers.py", line 139, in _convert_dataset image_data = tf.gfile.FastGFile(filenames[i], 'r').read()" 이곳에서 에러가 났다고 합니다. 문제 해결을 위해 구글링을 해보겠습니다.
"UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 0: invalid start byte" 이라는 에러인데 "download_and_convert_flowers.py", line 139, in _convert_dataset image_data = tf.gfile.FastGFile(filenames[i], 'r').read()" 이곳에서 에러가 났다고 합니다. 문제 해결을 위해 구글링을 해보겠습니다.
구글에서 "tensorflow utf-8" 로 검색을 해보겠습니다.



구글에서 "tensorflow utf-8" 로 검색을 해보겠습니다.

위 그림의 첫번째 링크(http://stackoverflow.com/questions/35513370/utf-8-decode-error-in-tensorflow-tutorial)를 클릭하면 본문에서 파일 오픈 옵션에서 'r' 대신 'rb'를 사용하라고 하네요. 저희도 139번 라인에 있는 "image_data = tf.gfile.FastGFile(filenames[i], 'r').read()" 를 "image_data = tf.gfile.FastGFile(filenames[i], 'rb').read()" 로 수정하겠습니다.

코드를 다시 실행해 보겠습니다.
python download_and_convert_data.py --dataset_name=flowers --dataset_dir=/tmp/flowers
그 다음 TFRecord 포멧으로 변환하는 과정에서 에러가 발생했네요. 이럴 때 포기 하지 마시고 어디서 에러가 발생했는지 찬찬히 살펴보겠습니다. 아나콘다 창에 보여지는걸 정리해보면
File "D:\utils\models-master\slim\datasets\download_and_convert_flowers.py", line 146,
위 파일 146번 라인에서
TypeError: 'jpg' has type <class 'str'>, but expected one of: ((<class 'bytes'>,),)
Type 에러가 발생했는데 jpg를 str 타입 말고 'bytes' 타입이 되어야 한다는 에러 메시지네요. '뭔말이야?' 라는 생각이 들죠? 당황하지 마시고 구글링을 해보면 아래와 같이 146번 라인 'jpg'앞에 b만 붙여주면 해결됩니다. b라는게 bytes로 type casting 해주나 봅니다.
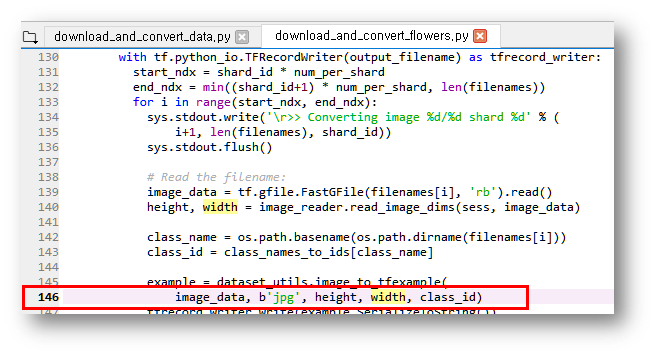
다시 실행해 보겠습니다.
python download_and_convert_data.py --dataset_name=flowers --dataset_dir=/tmp/flowers
휴~ 이제 에러가 나지 않는군요. 다운로드 지정한 폴더로 가보겠습니다. TFRecord 포멧 변환이 완료 되었습니다!

train용 TFRecord 5개와 validation용 5개 파일, 분류 클래스가 정의 되어 있는 labels 파일이 생성된 것을 확인할 수 있습니다. 이제 텐소플로우는 학습할 때 원본 이미지를 사용하지 않고 이 TFRecord 포멧 파일을 사용 할 겁니다.
코드를 수정해야 될 부분이 있다보니 포스팅이 길어졌네요. 학습 실습은 다음 포스팅에서 해보겠습니다!













작성자가 댓글을 삭제했습니다.
답글삭제안녕하세요. 딥러닝을 막 배우는 중인 학생인데요. 블로그대로 따라하다가 download_and_convert_flowers.py 이걸 키고 run 하는데 no module named datasets 이 뜨고 구글링 해서 해결방법을 찾아봤는데 먹히는게 없어서요.. 혹시 이런 문제는 없으셨는지 아니면 해결방법을 아시나 해서요
답글삭제저도 같은문제가 뜨는데 해결하셧나요???
삭제어 뭐지... 그냥 되는데요? ㄷㄷㄷ;
답글삭제slim 이 옛날에는 python 2.7이었는데 python3 으로 제공되고 있네요 ㅎㅎ 이제 그냥 바로 될거에요
삭제